Overview
This section explains how Restate is built today: a partitioned, log-centric runtime where events are synchronously replicated between Restate server nodes, and partition-processor state is periodically snapshotted to S3 for bounded, fast recovery. The description focuses on the current implementation and omits optional storage trade-offs.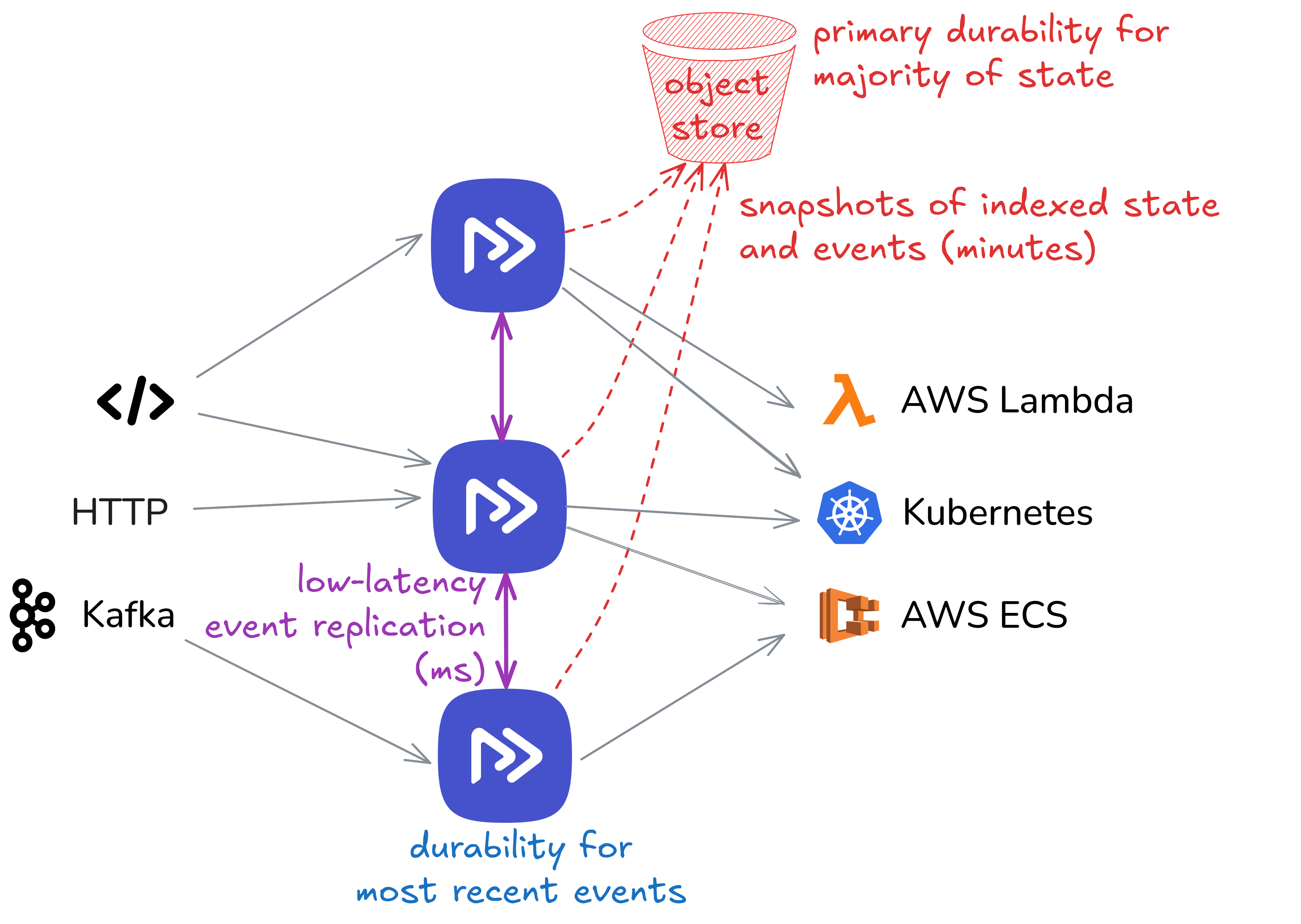
Components
At a high level, Restate interposes a log-first runtime between clients and your handlers, with clear separation of ingress, durability, execution, and control.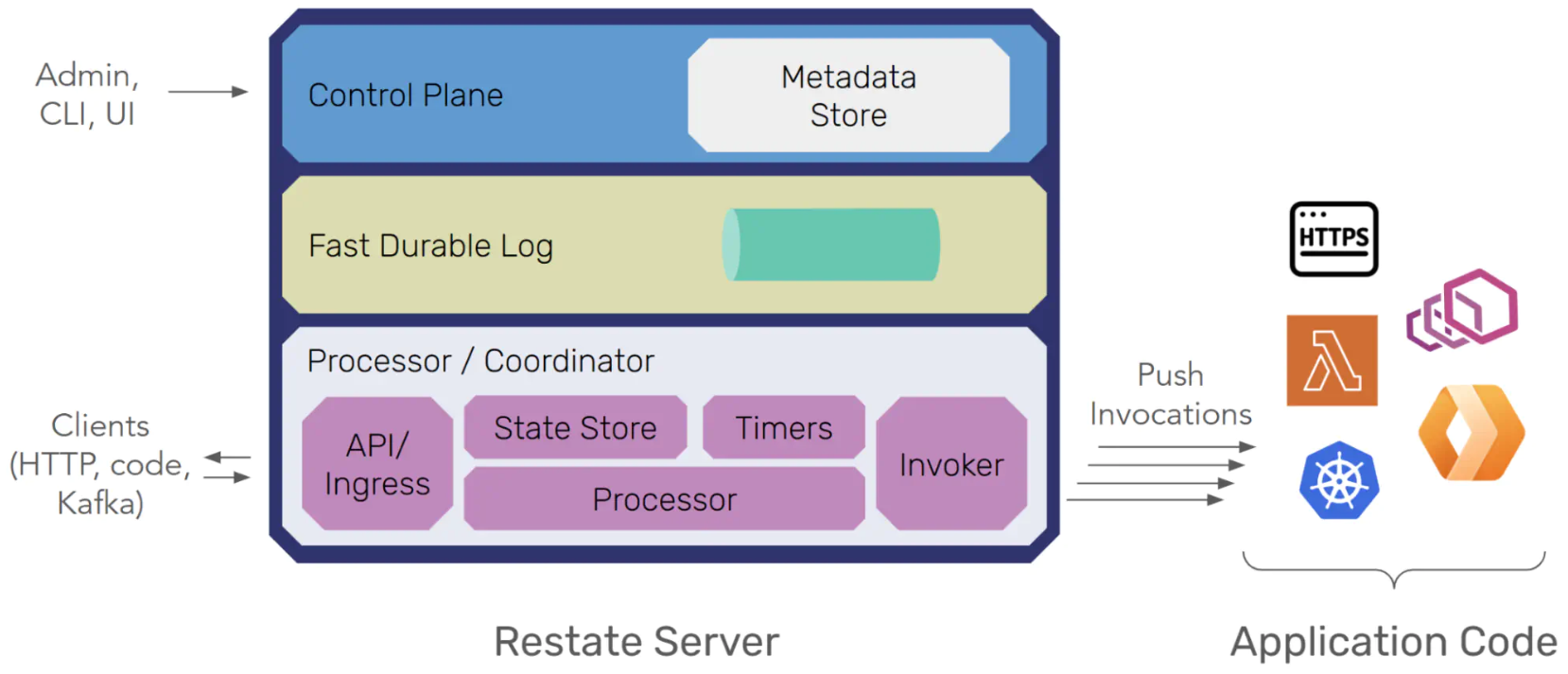
Ingress
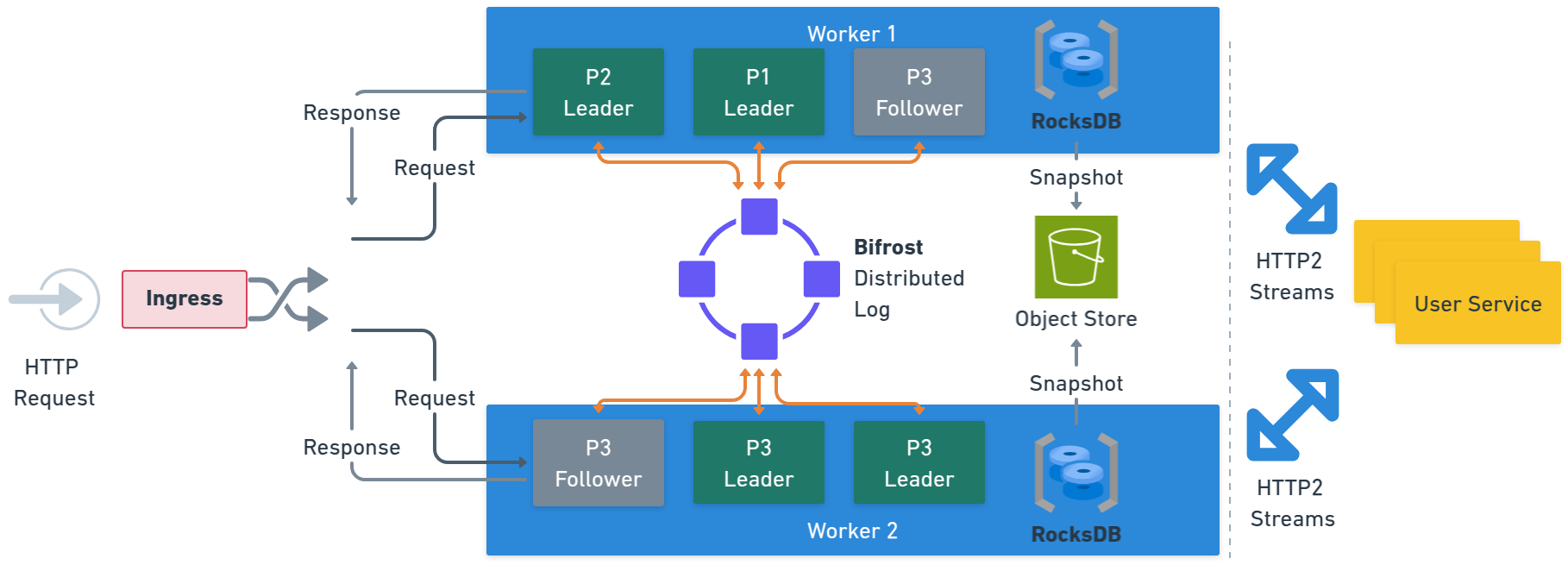
Ingress is the front door for client and internal calls, identifies the target service/handler and partition (via workflow ID, virtual-object key, or idempotency key), and forwards the call to the current leader of that partition. Ingress is leader-aware; when leadership changes due to failover or rebalancing, routing updates automatically without client involvement.Durable Log (“Bifrost”)
The log is the primary durability layer. Each partition has a single sequencer/leader that orders events and replicates them to peer replicas on other Restate nodes. A write is committed when a quorum of replicas acknowledges the append. Restate uses a segmented virtual log: the active segment receives appends; reconfiguration seals the active segment and atomically publishes a new segment as the head. Segmentation enables clean and fast leadership changes, placement updates, and other reconfiguration without copying data.Partition Processor
Every partition has one processor leader (and optional followers). The processor tails the log, invokes your handler code via a bidirectional stream, and maintains a materialized state cache in an embedded RocksDB. This cache holds journals, idempotency metadata, key-scoped state for virtual objects, and timer indices—everything required for low-latency execution. Followers track the same state and can become leader quickly on failure.Control Plane
The control plane holds cluster metadata (configurations, partition placement, epochs, segment descriptors) behind a consensus interface (built-in Raft). A cluster controller manages log nodes and processors and initiates failover when health checks fail. Strong consensus is confined to this metadata layer, and the data path “borrows” consensus in the form of a leader/epoch configuration which the control plane revokes and re-assignes upon failover, rebalancing, and other reconfigurations.Durability and storage model
The system treats the replicated log as ground truth and uses S3-backed snapshots to bound recovery time without introducing a second source of truth.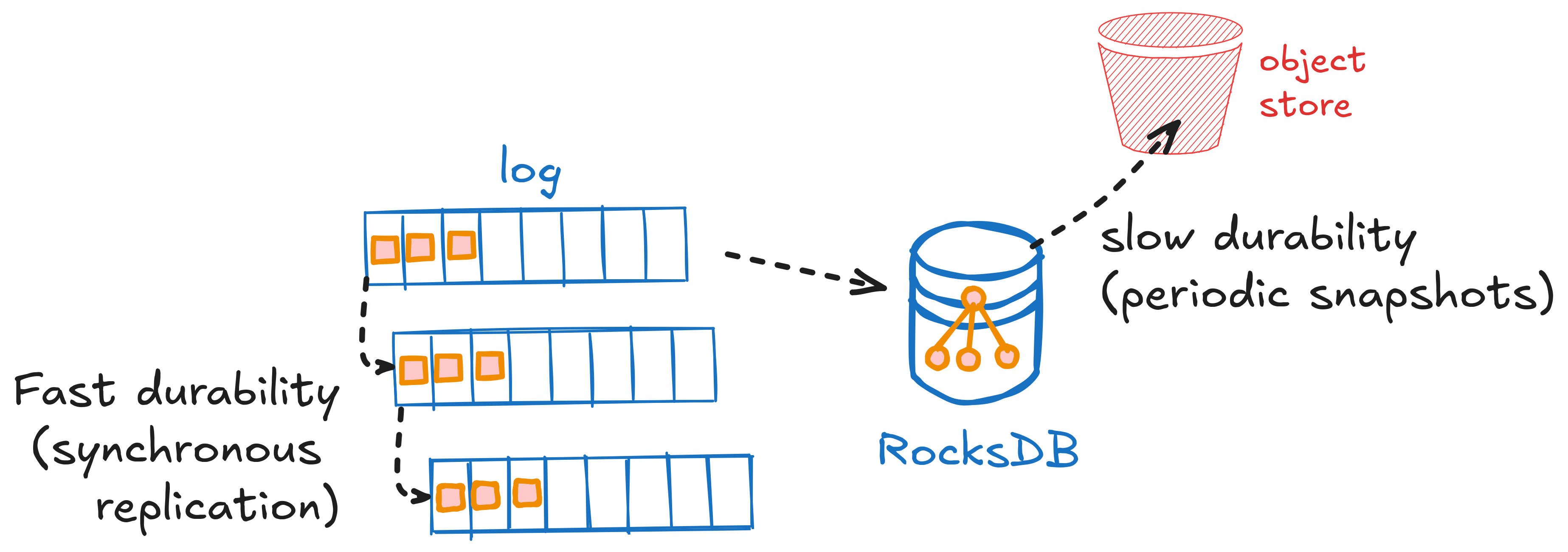
Hot-path durability
An operation “happens” when the partition leader appends its record to the log and receives quorum acks. That commit point defines the durable order of invocations, steps, state updates, messages, timers, and completions.Materializing state for fast access
The processor leader maintains a full cache of the partition’s materialized state in RocksDB for fast random reads and updates during execution. This cache is derivative—it can always be rebuilt from the log—and is not a second source of truth. In typical configurations, partitions also have processor followers, which maintain a materialization of the partition state, for fast failover.Recovery bounded by snapshots
Processors create periodic snapshots of their RocksDB partition store and upload them to S3. On restart or takeover, a fresh partition processor can download the latest snapshot and replay only the log suffix since the snapshot’s sequence number. Once the partition store state is considered safely persisted (based on the configured durability mode), the corresponding log entries can be trimmed to cap storage and replay cost. Partition processors fetch snapshots only when they were not previously a leader or follower and need to bootstrap a new copy of the partition state, or when they fall behind the log’s trim point.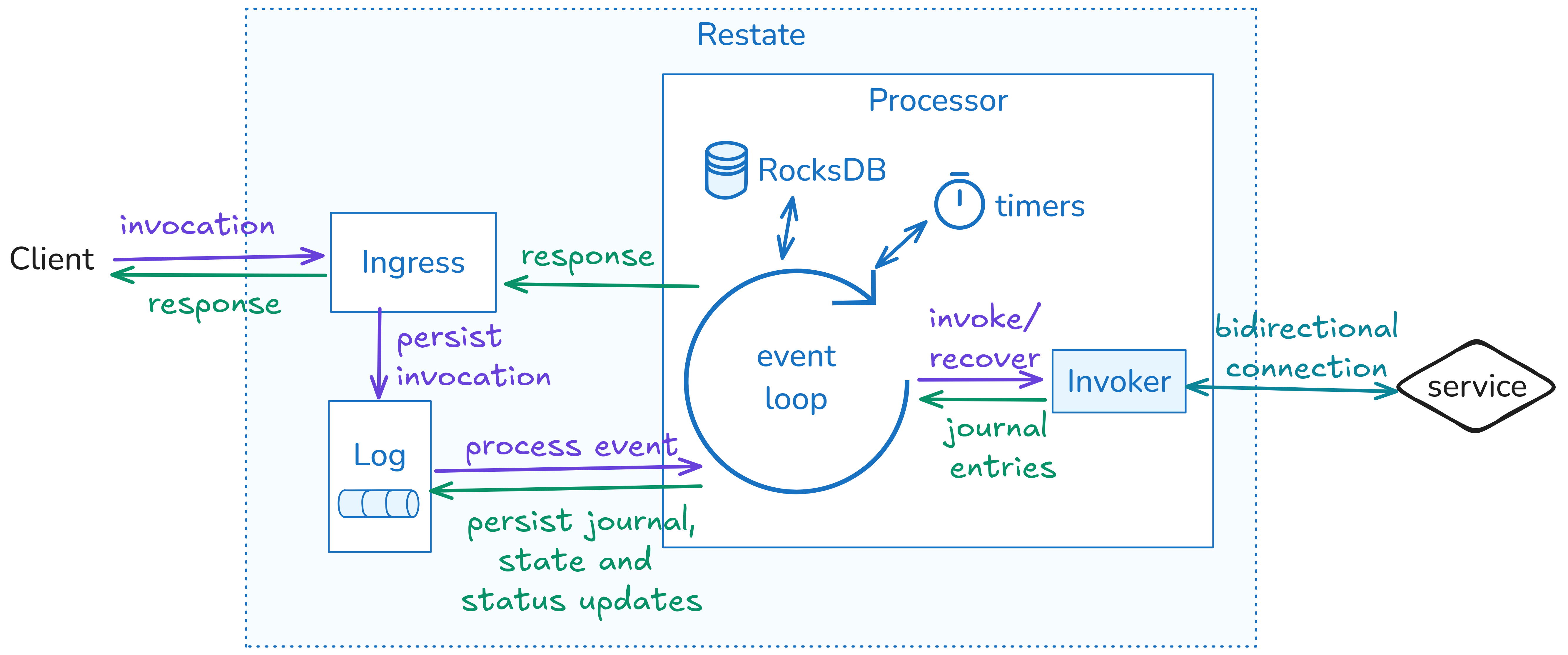
Partitioned scale-out and addressability
Restate scales by sharding orchestration and state by key, keeping hot paths partition-local and cross-partition work explicit.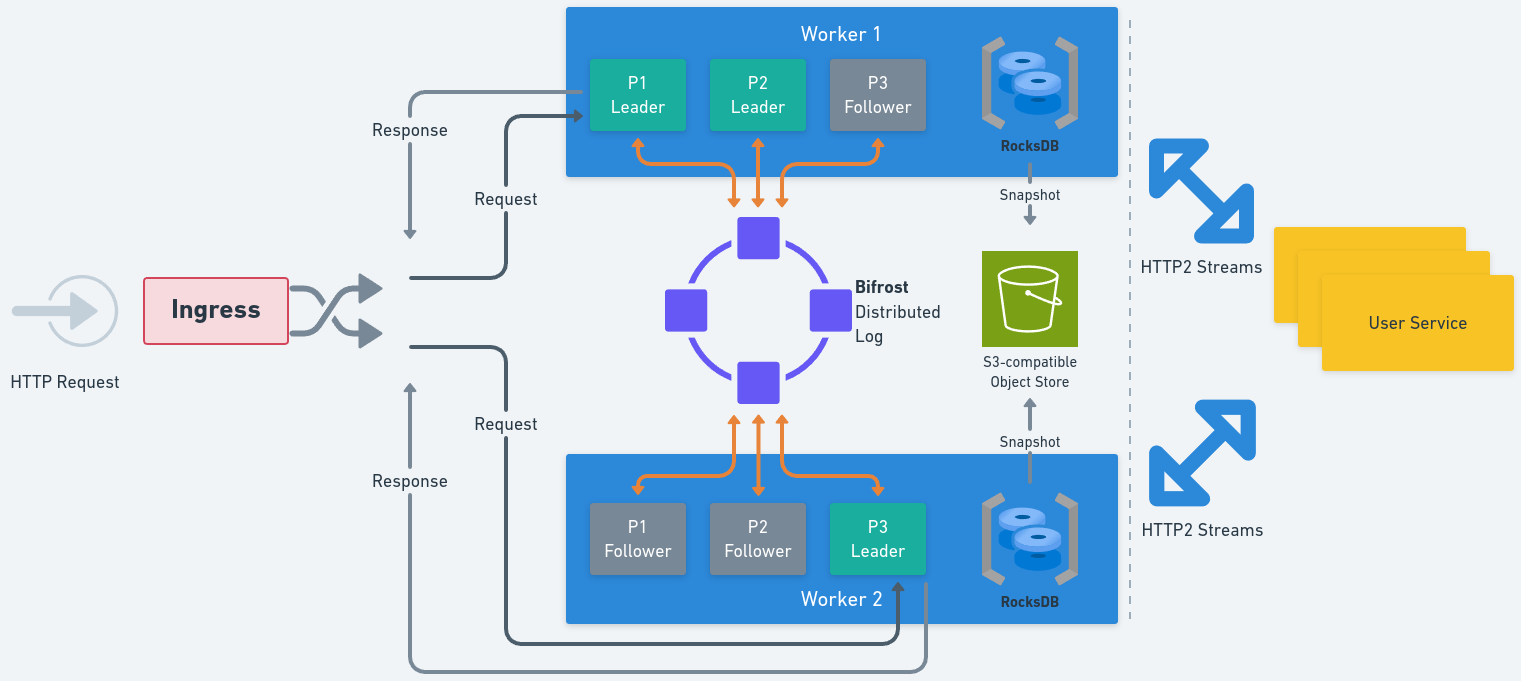
Keyed routing
Workflow IDs, virtual-object keys, or idempotency keys deterministically hash to a partition. Non-keyed invocations are placed for locality by the ingress. The invocation ID encodes the partition, enabling efficient subsequent routing and lookups.Co-sharding of orchestration and state
Each partition owns both orchestration (invocation lifecycle, journaling, timers) and the state cache for its keys. Steps, state updates, and timers for a key execute entirely within one partition—no cross-partition coordination is needed for the hot path.Cross-partition actions
When a handler targets a different key (e.g., sends a message or performs an RPC to another service keyed on a different partition), the event is recorded in the origin partition’s log and delivered exactly once to the destination partition via an internal shuffler. Delivery is addressed and deduplicated by sequence numbers; the receiving partition treats it as a normal log-first operation.Elastic operations
While the number of partitions is configured at cluster creation today, the addressing scheme and segment abstraction are designed so the system can migrate partitions or split key ranges in future versions without violating ordering or idempotency guarantees.Write path and step lifecycle
To make the mechanics concrete, the flow below traces an end-to-end invocation of processPayment keyed by idempotency key K.1
Client → Ingress (enqueue)
A client invokes processPayment with key K. The ingress hashes K to select the target partition and enqueues the invocation to that partition’s log.
2
Processor leader claims and starts execution
The partition’s processor leader consumes the enqueue event, checks its local idempotency state for K, and sees that K is not present for processPayment. It atomically records K (idempotency) and transitions the invocation to RUNNING, then opens a bidirectional stream to the target service endpoint and pushes the initial invoke journal entry to the handler.
3
Durable step commit (ctx.run)
As the service executes, it streams back a step result event (e.g., from
ctx.run). The processor appends this step journal entry to the log. The moment this append is replicated to quorum defines “the step happened.” From then on, the step will be recovered on retries and won’t be re-executed.4
Materialization and ack
When the processor subsequently reads the committed step event back from the log (confirming it still holds leadership), it adds the entry to the invocation’s journal state (and any relevant indexes) and acks the handler so the user code can proceed with the next step.
5
Other durable actions (state/timers/RPC/promises)
The same pattern applies to state updates, timers, inter-service RPC/messages, or durable promises/futures: each action is added to the log first, and upon reading the committed record, the processor applies it (e.g., updates key-scoped state, registers/fires a timer, routes an RPC to another partition via the internal shuffler, or resolves a promise).
6
Completion
When the handler finishes, the processor appends a Result event to the log. After reading that event back, it marks the invocation COMPLETE and returns the result to the client (or emits the completion signal for async flows).
7
Failures and retries (epoch fencing)
If execution fails at any point (process crash, stream loss, user exception), the processor dispatches a new attempt and attaches the full journal so far. Attempts carry monotonically increasing epochs; the processor rejects any events from superseded epochs (late messages from older attempts), preventing split-brain effects. This bookkeeping is partition-local and efficient because invocations are sticky to a single partition with a strong leader.
Failover and reconfiguration
Leader loss or placement changes trigger a sealed-segment handover and epoch fencing that keep ordering and exactly-once properties intact.Detection and triggering
The cluster controller heartbeats sequencers and processors. Partition processors and log servers additionally gossip their detection of peer failures for faster failover handling.Log failover
On reconfiguration, the controller seals the active segment (a quorum of replicas refuses further appends), determines the authoritative tail of the log segment, elects a new sequencer/replica set, and performs a metadata CAS to publish the new segment as head. Appenders and readers consult metadata and continue on the new head.
Processor failover
A follower (or a restarted processor) is promoted, obtains a new epoch, appends an epoch-bump record. The new leader ensures it can resume the log’s event stream (possibly restoring the latest S3 snapshot, if it was not previously a follower). Any late appends from superseded leaders or stale handler attempts (carrying lower epochs) are fenced at the epoch boundary and ignored.Routing continuity
Ingress consults the updated control-plane metadata and routes directly to the new leaders. Clients do not need to reconnect to different endpoints or re-negotiate sessions; failover is transparent at the API boundary.Nodes and roles
You’ll see many mentions of the terms server and node throughout this documentation. Generally, we use the term “server” to refer to a running instance of therestate-server binary. This binary can host multiple functions. When you start a single-node Restate server, for example when doing some local development or testing, you are hosting all the essential features in a single process. These include accepting incoming requests, durably recording events, processing work (delegating invocations to services, handling key-value operations), as well as maintaining metadata used internally by the system.
At its simplest, running a cluster is not that different - multiple nodes cooperate to share the responsibilities we mentioned earlier. This is accomplished by having multiple copies of the server process running on separate machines, although it is possible to create test clusters on a single machine. Nodes are therefore distinct instances of the Restate server within a cluster.
Restate clusters are designed to scale out in support of large deployments. As you add more machines, it becomes wasteful to replicate all the functionality across all the machines in a cluster, since not all features need to scale out at the same rate. Roles control which features run on any given node, enabling specialization within the cluster.
Here is an overview of the different roles that can run on a node:
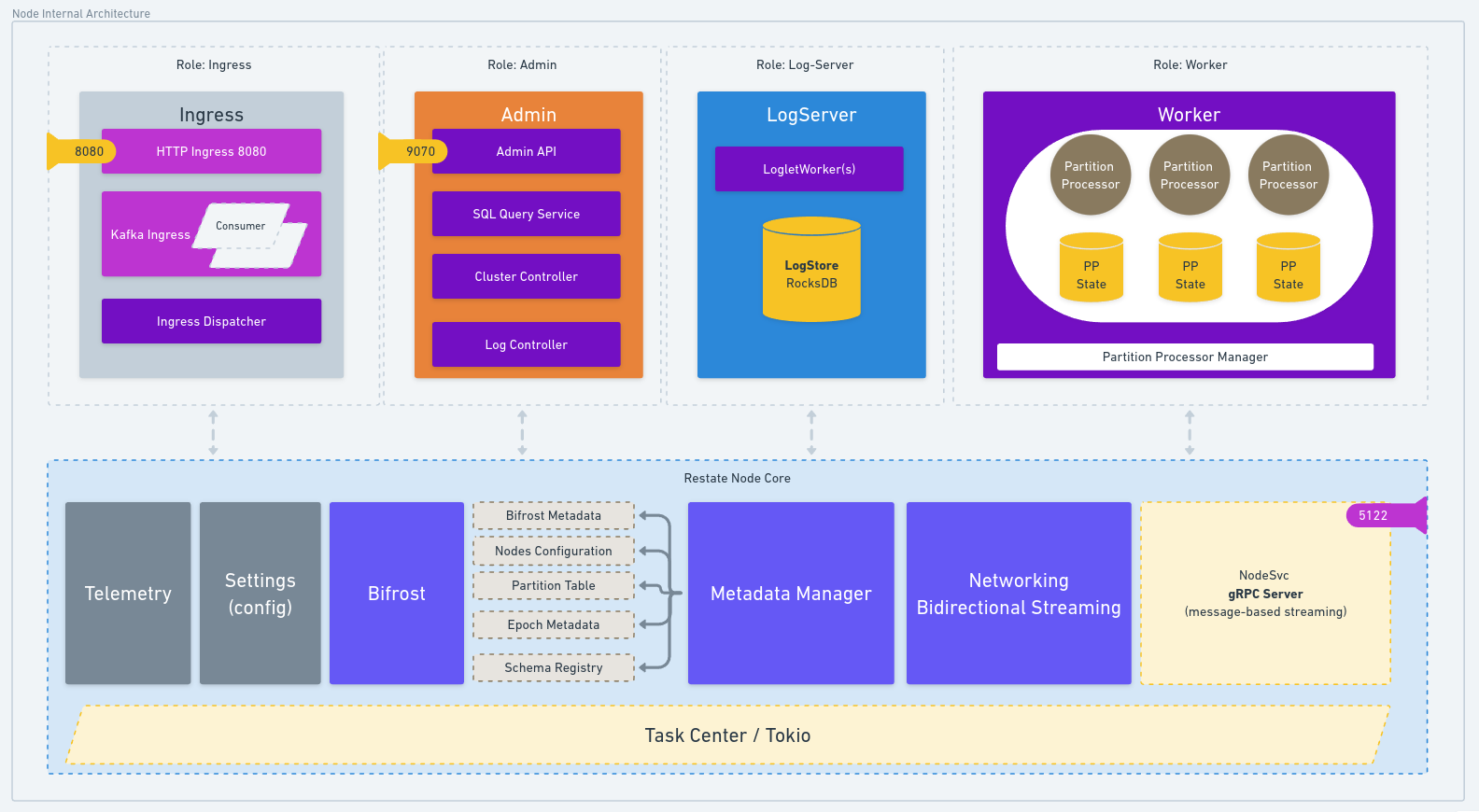
- Metadata server: the source of truth for cluster-wide information
- Ingress: the entry point for external requests
- Log server: responsible for durably persisting the log
- Worker: houses the partition processors
Metadata store
The Restate metadata store is part of the control plane and is the internal source of truth for node membership and responsibilities. It is essential to the correctness of the overall system: In a cluster this service enables distributed consensus about other components’ configuration. All nodes in a Restate cluster must be able to access the metadata store, though not all members of the cluster need to be part of hosting it. Restate includes a built-in Raft-based metadata store which is hosted on all nodes running themetadata-server role.
The metadata store is designed to support relatively low volumes of read and write operations (at least compared to other parts of Restate), with the highest level of integrity and availability.
Ingress
External requests enter the Restate cluster via the HTTP ingress component, which runs on nodes assigned thehttp-ingress role. Compared to other roles, the HTTP ingress role does not involve long-lived state and it can move around relatively freely, since it only handles ongoing client connections.
Log servers
Log server nodes running thelog-server role are responsible for durably persisting the log. If the log is the equivalent of a WAL, then partition stores are the materializations that enable efficient reads of the events (invocation journals, key-value data) that have been recorded. Depending on the configured log replication requirements, Restate will replicate log records to multiple log servers to persist a given log, and this will change over time to support maintenance and resizing of the cluster.
Workers
Nodes assigned theworker role run the partition processors, which are the Restate components responsible for maintaining the partition store.
Partition processors can operate in either leader or follower mode.
Only a single leader for a given partition can be active at a time, and this is the sole processor that handles invocations to deployed services.
Followers keep up with the log without taking action, and are ready to take over in the event that the partition’s leader becomes unavailable.
The overall number of processors per partition is configurable via the partition replication configuration option.