Infrastructure errors (transient) vs. application errors (terminal)
In Restate, we distinguish between two types of errors: transient errors and terminal errors.- Transient errors are temporary and can be retried. They are typically caused by infrastructure issues (network problems, service overload, API unavailability,…).
- Terminal errors are permanent and should not be retried. They are typically caused by application logic (invalid input, business rule violation, …).
Handling transient errors via retries
Restate assumes by default that all errors are transient errors and therefore retryable. If you do not want an error to be retried, you need to specifically label it as a terminal error (see below). Restate lets you configure the retry strategy at different levels: for the invocation and at the run-block-level.At Invocation level
Restate retries executing invocations that can’t make any progress according to a retry policy. This policy controls the retry intervals, the maximum number of attempts and whether to pause or kill the invocation when the attempts are exhausted. To see the current retry policy for your services, click on your service in the overview page of the UI: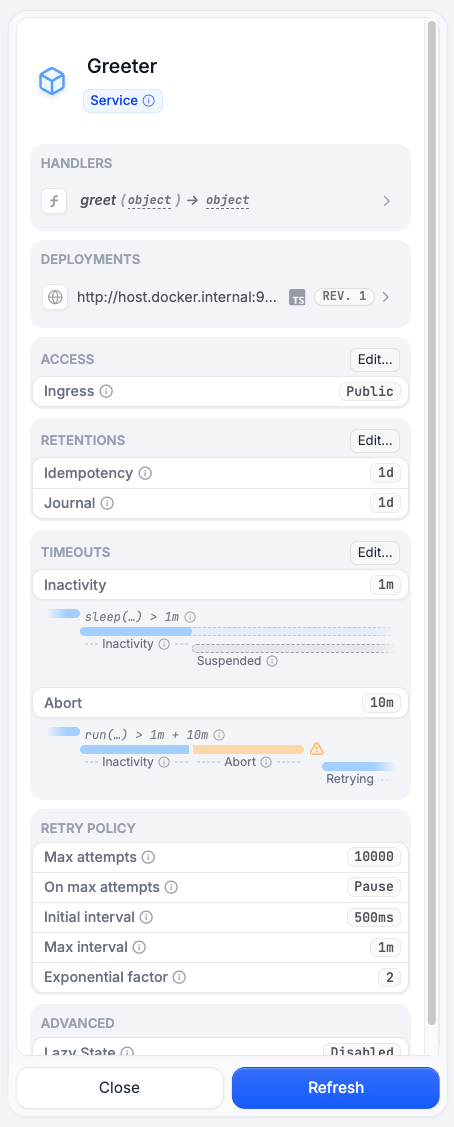
Configure for services/handlers
Configure for services/handlers
To configure the retry policy on a service/handler level, check retry service configuration.
Configure Restate server defaults
Configure Restate server defaults
The default retry policy will retry the invocation a limited number of times, after which the invocation will be paused if no progress can be made. To resume a paused invocation, check the resume documentation.Check the configuration reference for the Then run the Restate Server with:Or you can set these options via env variables:You can also retry forever, without ever pausing or killing the invocation:When a retry policy is unset, Restate by default will retry undefinitely, alike setting
default-retry-policy.You can change the default behavior via the restate-server configuration file:restate.toml
max-attempts = "unlimited".At the Run-Block-Level
Handlers use run blocks to execute non-deterministic actions, often involving other systems and services (API call, DB write, …). These run blocks are especially prone to transient failures, and you might want to configure a specific retry policy for them.Retryable errors with custom delay
Sometimes you need to control the retry timing dynamically, for example when an external API returns aRetry-After header. You can use RetryableError to tell Restate exactly when to retry.
This is primarily useful inside ctx.run blocks:
TerminalError which stops retries permanently, RetryableError tells Restate to retry after the specified delay. You can combine it with run retry options like maxRetryAttempts and maxRetryDuration to bound the total number of retries.
You can also throw RetryableError directly in handler code (outside of ctx.run), in which case the entire handler invocation will be retried after the specified delay.
Application errors (terminal)
By default, Restate retries all errors. In some cases, you might not want to retry an error (e.g. because of business logic, because the issue is not transient, …). For these cases you can throw a terminal error. Terminal errors are permanent and are not retried by Restate. You can throw a terminal error as follows:When you throw a terminal error, you might need to undo the actions you did earlier in your handler to make sure that your system remains in a consistent state.
Have a look at our sagas guide to learn more.
Cancellations are Terminal Errors
You can cancel invocations via the CLI, UI and programmatically. When you cancel an invocation, it throws a terminal error in the handler processing the invocation the next time it awaits a Promise or Future of a Restate Context action (e.g. run block, RPC, sleep,…;RestatePromise in TypeScript, DurableFuture in Java).
Unless caught, This terminal error will propagate up the call stack until it reaches the original caller.
Here again, the handler needs to have compensation logic in place to make sure the system remains in a consistent state, when you cancel an invocation.
Timeouts between Restate and the service
There are two types of timeouts describing the behavior between Restate and the service.Inactivity timeout
When the Restate Server does not receive a next journal entry from a running handler within the inactivity timeout, it will ask the handler to suspend. This timer guards against stalled service/handler invocations. Once it expires, Restate triggers a graceful termination by asking the service invocation to suspend (which preserves intermediate progress). By default, the inactivity timeout is set to one minute. You can increase the inactivity timeout if you have long-runningctx.run blocks, that lead to long pauses between journal entries. Otherwise, this timeout might kill the ongoing execution.
Abort timeout
This timer guards against stalled service/handler invocations that are supposed to terminate. The abort timeout is started after the ‘inactivity timeout’ has expired and the service/handler invocation has been asked to gracefully terminate. Once the timer expires, it will abort the service/handler invocation. By default, the abort timeout is set to ten minutes. This timer potentially interrupts user code. If the user code needs longer to gracefully terminate, then this value needs to be set accordingly. If you have long-runningctx.run blocks, you need to increase both timeouts to prevent the handler from terminating prematurely.
Configuring the timeouts
As with the retry policy, you can configure these timeouts on specific handlers, on all the handlers of a service, or globally in the Restate configuration directly.Configure for services/handlers
Configure for services/handlers
To configure these timeouts on a service/handler level, use the UI or check timeouts service configuration.
Configure Restate server defaults
Configure Restate server defaults
Via the Both timeouts follow the jiff format.Or set it via environment variables, for example:
restate-server configuration file:restate.toml
Common patterns
These are some common patterns for handling errors in Restate:Sagas
Have a look at the sagas guide to learn how to revert your system back to a consistent state after a terminal error. Keep track of compensating actions throughout your business logic and apply them in the catch block after a terminal error.Dead-letter queue
A dead-letter queue (DLQ) is a queue where you can send messages that could not be processed due to errors. You can implement this in Restate by wrapping your handler in a try-catch block. In the catch block you can forward the failed invocation to a DLQ Kafka topic or a catch-all handler which for example reports them or backs them up.Catching failed invocations before handler execution starts
Catching failed invocations before handler execution starts
Some errors might happen before the handler code gets invoked/starts running (e.g. service does not exist, request decoding errors in SDK HTTP server, …).
By default, Restate fails these requests with The other errors mainly occur due to misconfiguration of your setup (e.g. wrong service name, wrong handler name, forgot service registration…).
You cannot handle those.
400.Handle these as follows:- In case the caller waited for the response of the failed call, the caller can handle the propagation to the DLQ.
- If the caller did not wait for the response (one-way send), you would lose these messages.
- Decoding errors can be caught by doing the decoding inside the handler. The called handler then takes raw input and does the decoding and validation itself. In this case, it would be included in the try-catch block which would do the dispatching: